Every call to Claude, GPT, or Codex costs money. Most applications make far more calls than they need to — and each one is billed. OpenSource Technologies engineers the code that quietly eliminates the waste, so your AI stays powerful and your invoice stays sane.
By OpenSource Technologies Engineering & AI Strategy Team
KEY NUMBERS — WHAT UNOPTIMIZED APPS WASTE
01 — THE PROBLEM
You’re Not Paying for AI. You’re Paying for Waste.
When a business integrates an AI API — whether that’s Anthropic’s Claude, OpenAI’s GPT-4o, or Codex for code generation — the billing is straightforward: you pay per token. Input tokens, output tokens, every single exchange with the model.
What isn’t straightforward is how quickly those tokens add up when the application isn’t engineered carefully. Here’s what silently inflates API bills every month:
- Sending the same large system prompt on every request — instead of caching it
- Asking the model the same question twice — because no response was stored
- Using GPT-o3 or Claude Opus for simple tasks — that Haiku or GPT-4o Mini handles equally well
- Making 100 individual API calls — when one batch request does the same job at half the price
- Bloated, unstructured prompts — that force the model to spend tokens figuring out what you want
“The AI itself isn’t expensive. Unengineered usage of the AI is expensive. Every architectural decision your development team makes either compounds cost or eliminates it — and most teams are making those decisions without thinking about API economics at all.”
This is exactly where OpenSource Technologies comes in. With 14+ years of software engineering experience and deep hands-on work with every major AI API, OST builds and optimizes the code layer that sits between your product and the AI model — the layer that determines how much you pay.
02 — THE ENGINEERING TECHNIQUES
7 Ways OST Reduces Your AI API Costs Through Code
These aren’t theoretical optimizations. These are architectural patterns OST implements in client applications across healthcare, fintech, e-commerce, and more — each one directly reducing the number or size of API calls made to Claude, GPT, and Codex.
01 — Prompt Caching: Stop Resending What You Already Sent
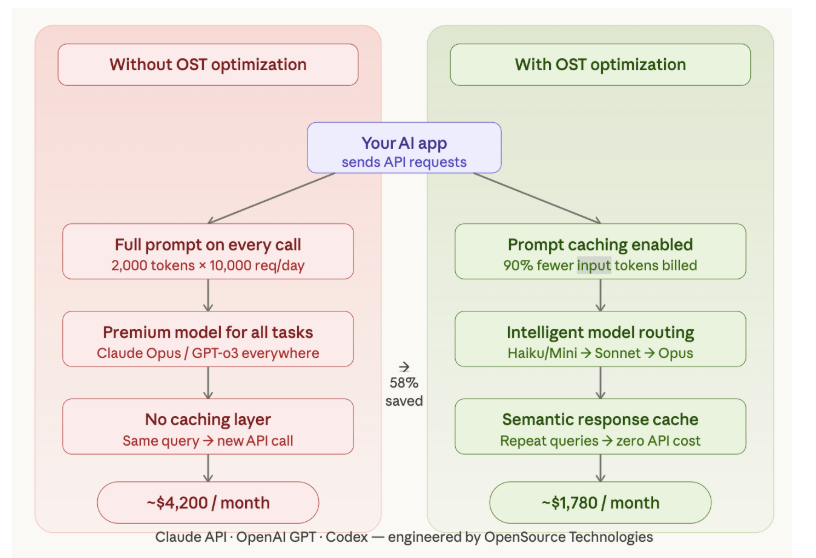
Most AI-powered apps include a large system prompt: instructions, context, persona, rules. If that prompt is 2,000 tokens and your app makes 10,000 calls per day, you’re paying for 20 million input tokens just to repeat yourself.
OST implements Anthropic’s Prompt Caching feature and equivalent mechanisms for OpenAI, storing the static portion of your prompt server-side so it only counts as full input tokens once. Subsequent calls reference the cache at a fraction of the cost — up to 90% reduction on cached input tokens for Claude.
02 — Semantic Response Caching: Don’t Ask Twice
If a user asks ‘How do I reset my password?’ and 500 other users ask the same thing this week, why make 501 API calls? OST builds semantic caching layers using vector similarity search — when an incoming query is semantically close enough to a previously answered one, the cached response is returned instantly. No API call made, no token spent.
This is especially powerful for customer-facing AI assistants, documentation chatbots, and code suggestion tools where query patterns are highly repetitive.
03 — Batch API Processing: Pay Half Price for the Same Work
Not every AI task needs an answer in under a second. Code review pipelines, document summarization, nightly data enrichment, automated report generation — these workloads can wait. OST routes these tasks through Anthropic’s Message Batches API and OpenAI’s Batch API, which process requests asynchronously and charge 50% less per token than real-time endpoints. Same quality output, half the price.
04 — Intelligent Model Routing: Match Task to Model
Claude Opus and GPT-o3 are extraordinary for complex reasoning — and the most expensive models on the market. OST builds model routing middleware that classifies each incoming request by complexity, then dispatches it to the appropriately priced model. Simple queries go to Claude Haiku or GPT-4o Mini. Only truly complex reasoning reaches premium models. Result: 40–60% cost reduction with no measurable difference in output quality for routed tasks.
05 — Token Optimization: Engineer Prompts Like Code
Prompts are not just instructions — they’re billable lines. A poorly written 800-token prompt that says the same thing as a clean 200-token version costs 4× more, every single call. OST’s engineers treat prompt design as a first-class engineering discipline. We audit your existing prompts, remove redundancy, restructure for clarity, and define output schemas that minimize verbose model responses.
06 — Streaming + Early Termination: Stop When You Have Enough
Standard API calls wait for the model to finish generating the entire response before returning it. OST implements streaming responses across Claude and OpenAI APIs, and adds early termination logic: when a structured answer is complete (a JSON object closes, a code block ends), the stream stops. You pay only for what was actually generated and used.
07 — Retry Architecture & Rate Limit Engineering
Naive retry logic is a silent budget destroyer. An unhandled rate limit error that triggers 5 automatic retries multiplies your API costs instantly. OST implements exponential backoff, request deduplication, and intelligent rate limit awareness that prevents retry storms — eliminating a category of waste that most teams don’t even know is happening.
03 — SAVINGS BREAKDOWN
What Each Technique Actually Saves
Here’s a practical summary of each optimization, the APIs it applies to, and the typical cost reduction OST achieves for clients.
| Technique | APIs | Typical Savings | Best Use Case |
|---|---|---|---|
| Prompt Caching | Claude – OpenAI | ↓ 70–90% input | Apps with large static system prompts |
| Semantic Response Caching | Claude – OpenAI – Codex | ↓ 30–60% calls | Chatbots, FAQ bots, code tools |
| Batch API Processing | Claude – OpenAI | ↓ 50% flat rate | Code review, doc gen, nightly jobs |
| Model Routing | Claude – OpenAI – Codex | ↓ 40–60% spend | Multi-purpose AI platforms |
| Token / Prompt Optimization | Claude – OpenAI – Codex | ↓ 40–75% per call | All AI-integrated applications |
| Streaming + Early Termination | Claude – OpenAI | ↓ 10–30% output | Structured output, code generation |
| Retry & Rate Limit Engineering | Claude – OpenAI – Codex | Eliminates dupes | High-volume production apps |
04 — API DEEP DIVE
Claude, GPT & Codex: Where the Savings Differ
Anthropic Claude API
Claude’s pricing model makes it uniquely well-suited to caching strategies. Prompt Caching is a first-class feature — cache writes cost 25% more than standard input, but cache reads cost just 10% of standard price. For applications with consistent, large system prompts, OST engineers cache-aware request patterns from day one. Claude’s Message Batches API offers 50% off all tokens for async workloads — OST maps your task types and routes every eligible workload automatically.
OpenAI GPT-4o & GPT-4o Mini
OpenAI’s pricing ladder creates a natural optimization opportunity through model routing. OST implements routing logic that sends the majority of requests to GPT-4o Mini — roughly 15× cheaper than GPT-4o for many tasks — while reserving full GPT-4o for richer reasoning. OpenAI’s Batch API also provides a 50% discount for async workloads.
OpenAI Codex & Code Generation APIs
Codex-style APIs carry a specific cost pattern: context window bloat. Sending an entire codebase as context for a function-level suggestion is expensive and unnecessary. OST builds intelligent context windowing — extracting only the relevant file, function signatures, and type definitions the model actually needs. This reduces input tokens for code generation by 60–80% with no loss in output quality, and often improved accuracy.
05 — HOW OST DELIVERS THIS
OST Doesn’t Just Build AI Apps. We Engineer Them to Cost Less.
Most development agencies will integrate an AI API into your product and hand it over. The implementation works. The bills arrive. The bills grow. Nobody touches it again.
OpenSource Technologies takes a different approach. Every AI integration we build is designed with API economics as a first-class constraint — not an afterthought.
API Audit & Cost Mapping
We start by profiling your existing AI API usage — identifying which calls are redundant, which prompts are bloated, and which models are being over-used. We produce a cost map before writing a single line of new code.
Architecture Design for Cost Efficiency
Caching layers, model routers, batch queues — we design the infrastructure around your usage patterns before building, not after. The right architecture saves money from the very first production request.
Ongoing Monitoring & Continuous Optimization
We instrument every AI call with cost tracking. As usage grows and patterns shift, OST’s team identifies new optimization opportunities proactively — so your cost-per-request trends down even as your user base grows.
Cross-API Expertise
Whether you’re on Claude, GPT, Codex, or a combination, OST has worked with all of them in production. We know which features to use, which pricing traps to avoid, and which model is the right fit for each layer of your application.
Our clients span healthcare, fintech, e-commerce, EdTech, and startups — all using AI APIs at scale. In every case, the engineering investment in API cost optimization has returned multiples in monthly savings within the first quarter.
READY TO OPTIMIZE?
Your AI API Bill Could Be Significantly Smaller.
Let OST do a free 30-minute audit of your current Claude, GPT, or Codex API usage. We’ll show you exactly where the waste is — and what it would take to eliminate it.
Website: https://ost.agency
AI Services: ost.agency/services/ai-consulting-and-implementation
Contact: ost.agency/contactus
Phone: +1 (833) 678-2402 | info@ost.agency



